AI配音的技术演进:从文本转语音到情感模拟
AI配音已从简单的文本转语音(TTS)演进为能够克隆音色并实时调节情感的生成式音频技术。到2026年3月,它已成为游戏开发、有声书和企业内容生产的底层基础设施。其核心商业价值在于将音频生产的时间成本降低了 90% 以上,并实现了极高的内容迭代效率。
AI配音的本质是概率分布的模拟

系统通过分析数万小时的人类语音样本,学习音高、时长、能量及频谱特征,利用扩散模型(Diffusion Model)或 Transformer 架构重建波形。目前的技术重心已从“声音像”转向“情感对”。AI 开始根据上下文语义自动判断语气,例如在特定语境下自动加入轻微叹息或激昂呐喊,减少了人工手动调整每个音节参数的繁琐工作。
主流工具的功能路径与局限
目前 ElevenLabs、Microsoft Azure AI Speech 及火山引擎等工具的功能路径高度一致:上传 1-5 分钟样本进行克隆 $\rightarrow$ 输入文本 $\rightarrow$ 选择情感标签 $\rightarrow$ 生成音频。这类工具适用于快速原型开发和低预算短视频,但在处理“极度悲痛中强颜欢笑”等复杂情感转折时,依然存在明显的机械感。
商业级 AI 配音的精细化调优工作流
要将 AI 配音提升至商业级水准,必须放弃“一键生成”,进入精细化调优阶段。以下是具体的操作流程:
首先是文本语义标注
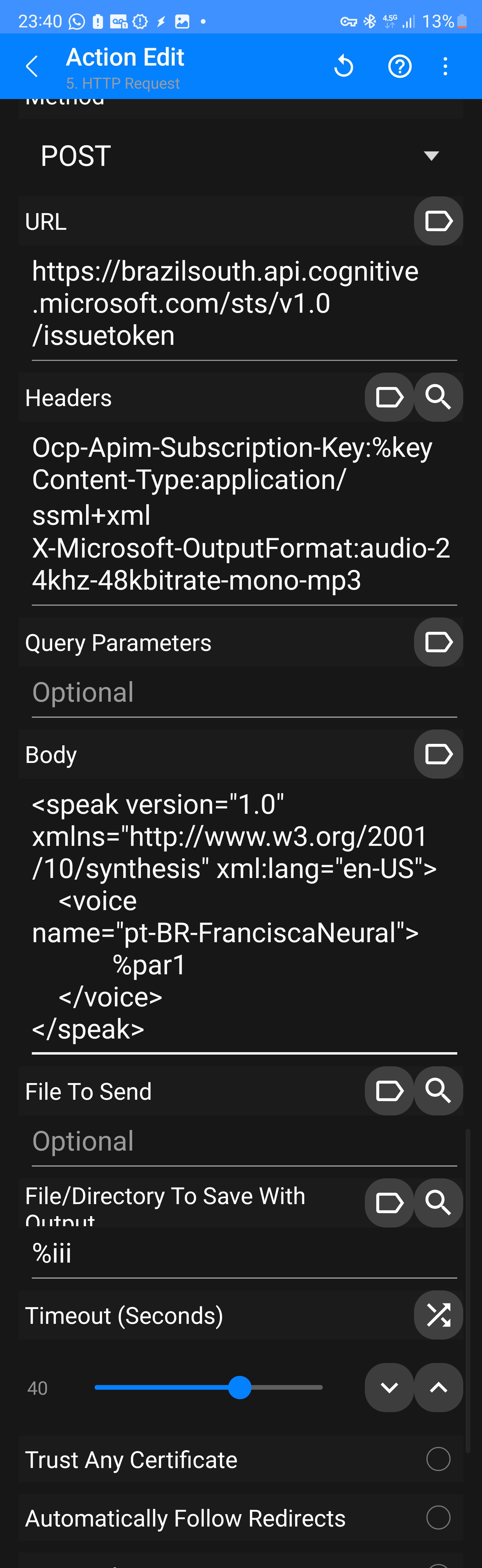
<emphasis level="strong"> 标记强调词,或插入 <break time="500ms" /> 强制停顿。遇到多音字时,手动改为同音字或使用音标,确保 AI 能够感知语气起伏。
其次是音色克隆的参数微调
样本纯净度直接决定最终质量,建议选取 3 分钟以上、采样率 48kHz 以上且无背景噪音的平稳人声。上传后需重点调节“稳定性(Stability)”和“相似度(Similarity)”参数。
| 应用场景 | 稳定性设置 | 预期效果 |
|---|---|---|
| 播报/企业培训 | 70% 以上 | 语调平稳,无波动,专业感强 |
| 剧情/情感对白 | 30% - 40% | 增加呼吸感和语调漂移,更自然 |
最后是多轨分层合成与后期润色
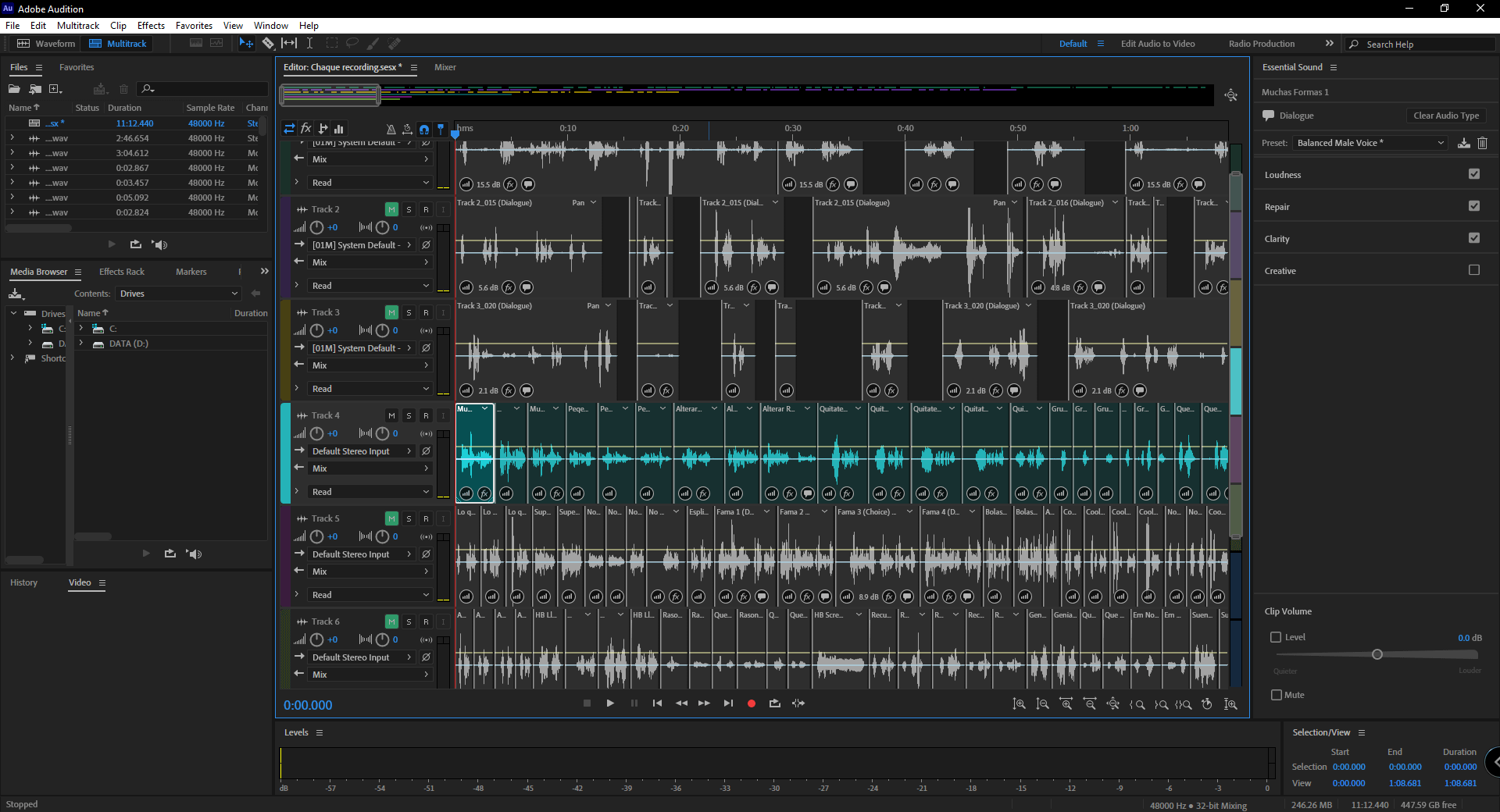
人机边界:AI 配音与真人配音的商业抉择
真人配音与 AI 配音在商业应用上存在明显边界。真人配音具备无可替代的情感深度和即兴处理能力,是顶级广告的首选;而 AI 配音则在标准语调和重复性任务中表现出色。
在游戏行业,AI 配音的渗透伴随着“声音同质化”问题。当多个角色基于相似模型生成时,即便音高不同,其底层语调逻辑一致,会导致玩家产生诡异的重复感,削弱角色的独特性。
不适合 AI 的特定场景
- 极高情感密度的戏剧冲突: 如绝望中的低声啜泣,涉及细微的肌肉颤抖。
- 强实时互动场景: 现场主持等需要捕捉幽默和氛围的瞬间。
- 品牌核心竞争力声音: 高端奢侈品广告,需要触动灵魂的灵光瞬间。
面对普及,建议构建“人机协作”流程

由 AI 处理 80% 的基础铺垫(如背景交代、通用对白),将 20% 的核心情感点交给顶级配音演员精修。这种混合模式能兼顾生产效率与艺术上限。
如何解决 AI 配音的“电音感”或金属共振?
首先检查原始样本的采样率是否达到 48kHz 且无噪音;其次适度提高“稳定性”参数;最后在 DAW 软件中使用均衡器(EQ)削减高频刺耳部分,并添加少量环境混响。
SSML 标记在所有 AI 配音工具中都通用吗?
不完全通用。虽然 SSML 是标准协议,但不同厂商(如 Azure 与 ElevenLabs)对具体标签的支持程度和生效权重有所不同,建议在正式生成前进行小段落测试。
实施建议:从全能音色转向“声音矩阵”
如果你准备升级产品语音版,不要追求单一的全能音色,而应建立“声音矩阵”。针对不同功能模块配置稳定性不同、音色差异明显的 AI 角色,并通过 SSML 精细控制。