从随机抽卡到精准控制:AI绘画的范式转移
AI 绘画已从早期的“随机抽卡”进化为高度可控的专业生产力工具。其核心逻辑是实现了从随机生成到精准控制的范式转移:早期的 Midjourney 或 Stable Diffusion 依赖概率分布,结果具有不可预测性;而到 2026 年,随着 ControlNet 的深度集成和多模态大模型的原生支持,像素级引导已成为可能,这使得 AI 绘画能够正式进入工业级生产管线。
底层原理:扩散模型如何生成图像
理解扩散模型(Diffusion Models)的底层原理是掌握该技术的关键。
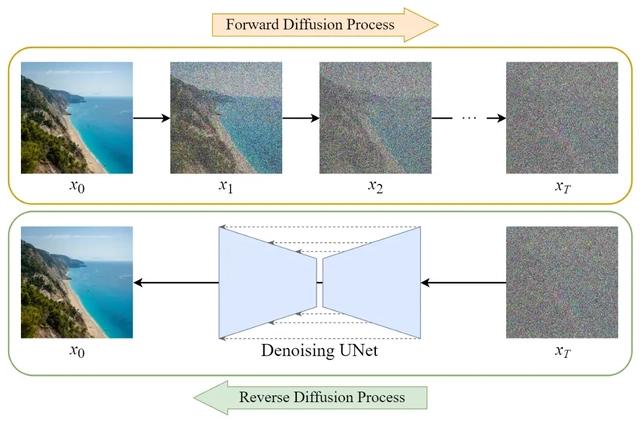
模型通过“前向过程”给图像添加噪声直至混沌,再通过“反向过程”学习剔除噪声以还原图像。当输入“赛博朋克风格的上海街头”时,AI 并非在数据库中拼接碎片,而是在高维潜空间(Latent Space)中寻找符合词汇特征的数学分布,并将其从噪声中引导出来。这解释了为何 AI 能生成原创图像而非简单复制。
主流 AI 绘画生态阵营对比
目前 AI 绘画生态分化为三个阵营,分别在审美、控制力与理解力上各有侧重。
| 阵营/工具 | 核心优势 | 主要劣势 | 适用场景 |
|---|---|---|---|
| Midjourney v7 | 极高审美上限,视觉冲击力强 | 闭源,缺乏细粒度控制 | 创意海报、艺术探索 |
| Stable Diffusion 3.5+ | 开源生态,支持LoRA微调,精准控制 | 学习曲线陡峭,需硬件支持 | 商业项目、角色一致性创作 |
| DALL-E 4 | 指令理解力最强,易用性极高 | 画风趋同,灵气不足 | 快速概念原型、草图构建 |
实操指南:Stable Diffusion + ControlNet 精准创作路径
若要实现精准创作,推荐采用 Stable Diffusion + ControlNet 的实操路径,以解决手指畸形和构图不可控的痛点。
第一步:构建骨架引导

此步骤旨在锁定几何结构,防止物体位置随机漂移。若预处理器选择错误,图像易出现拉伸或断裂。
第二步:配置提示词权重
正向提示词应遵循“主体 + 环境 + 光影 + 艺术风格 + 技术参数”结构。例如:
a hyper-realistic portrait of a girl, cinematic lighting, soft rim light, 8k resolution, shot on 35mm lens同时,负面提示词(Negative Prompt)用于过滤低级错误,建议加入 (worst quality, low quality:1.4), deformed iris, extra fingers 等。其中 :1.4 为权重系数。采样器推荐 DPM++ 2M Karras,步数设在 20-30 步。
第三步:通过 LoRA 模型注入特定风格

当通用模型无法维持人物面孔或冷门画风时,需加载 .safetensors 格式的 LoRA 权重文件。建议将权重设在 0.6 到 0.8 之间。权重直接开到 1.0 容易导致色彩崩坏或过度饱和,微调权重能让特征与基础模型(Checkpoint)自然融合。
第四步:局部修复(Inpainting)

幅度过高会生成无关物体,过低则无变化。通过多次小幅迭代,可将画面细节与全局光影融合,消除接缝感。
AI 绘画的局限性与认知升级
AI 绘画并非万能,在两类场景下效率较低:一是极高精度的工业设计(无法提供毫米级工程尺寸),二是需要极致情感表达的私人定制(缺失“创作者心境”)。
初学者应警惕“技术替代心理”。事实上,AI 降低了实现门槛,却提高了审美和筛选门槛。正如摄影术迫使绘画从“记录真实”转向“表达意识”,AI 绘画也将重心从“如何画”转移到了“画什么”。
关于版权争议如何看待?
这更像是一种数字化时代的风格解构。AI 学习的是规律而非具体像素,尽管法律界定仍处于灰色地带,但越来越多的艺术家通过训练专属 LoRA 模型来声明“数字版权”,将 AI 视为画笔而非替代品。
如何快速提升 AI 绘画的质量?
建议放弃背诵“万能提示词词典”,因为模型更新会导致词典失效。更有效的方法是学习摄影光影术语、艺术史流派特征和电影镜头语言,将具体的视觉知识转化为精准的引导词。